

Large language models (LLMs) have revolutionized the field of natural language processing (NLP), with applications ranging from chatbots and machine translation to text summarization and content creation. However, deploying these computationally intensive models into production requires specialized inference servers that can deliver high performance, scalability, and efficiency. This essay compares four popular inference servers for LLM operationalization: NVIDIA Triton, TensorRT, Apache MXNet Serving, and ONNX Runtime.
NVIDIA Triton
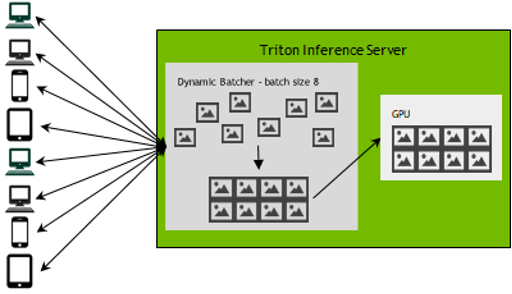
Triton is an open-source inference server optimized for GPUs, making it ideal for large and complex LLMs. It supports multiple frameworks (TensorFlow, PyTorch, ONNX) and offers features like dynamic batching, model versioning, and load balancing. Triton excels in performance, particularly for NVIDIA GPUs, and provides extensive configurability for fine-tuning inference pipelines. However, its setup and management can be complex, and it may not be as efficient for CPU-based deployments.
TensorRT
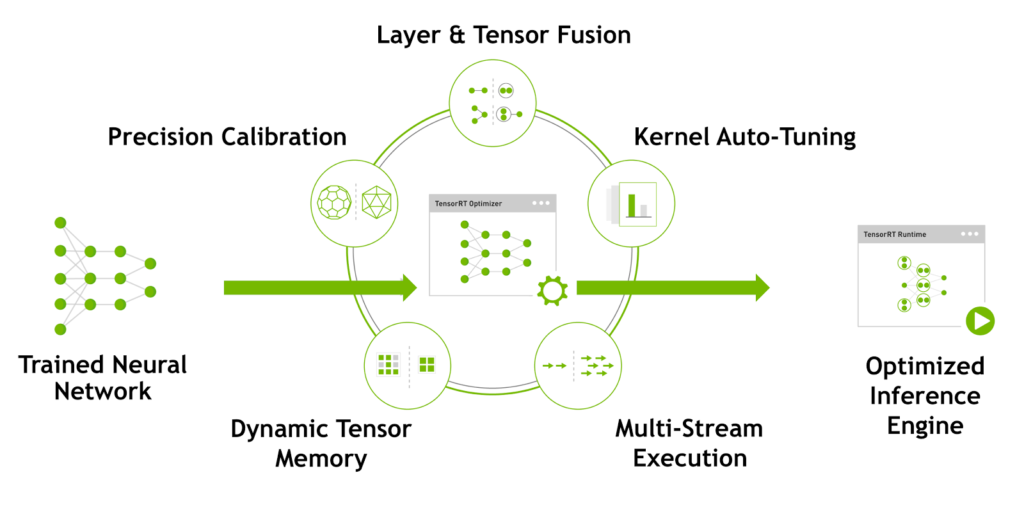
TensorRT is a high-performance inference engine from NVIDIA that converts trained models into optimized formats for deployment on GPUs, CPUs, and embedded devices. It offers various optimization techniques such as quantization, pruning, and layer fusion, resulting in significant performance gains over unoptimized models. TensorRT is well-suited for NVIDIA GPUs and provides a good balance between performance and ease of use. However, it is limited to NVIDIA hardware and may not be suitable for models not compatible with its optimization techniques.
Apache MXNet Serving
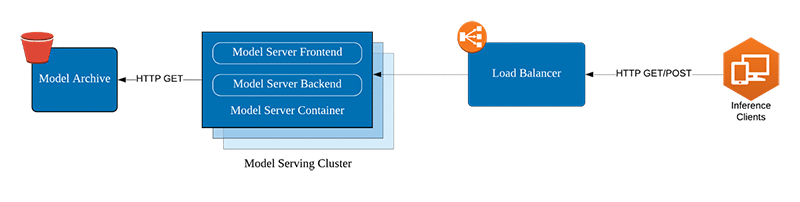
MXNet Serving is a flexible and lightweight inference server supporting diverse frameworks and models (MXNet, TensorFlow, PyTorch, ONNX). It offers features like multi-model serving, load balancing, and health checks, making it suitable for deploying a variety of LLMs. MXNet Serving is known for its ease of use and portability across different platforms. However, its performance may not match Triton or TensorRT for complex LLMs, and it may require additional configuration for optimal resource utilization.
ONNX Runtime
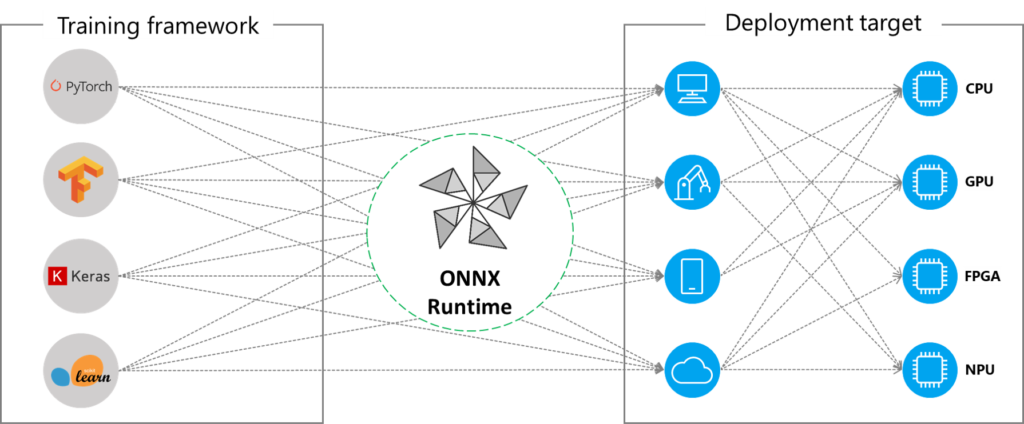
ONNX Runtime is a universal runtime environment for running ONNX models, a vendor-neutral format for representing deep learning models. It supports various platforms (Linux, Windows, macOS, Android, iOS) and hardware (CPUs, GPUs, mobile devices), making it highly portable and versatile. ONNX Runtime is known for its ease of deployment and wide platform compatibility. However, its performance may be lower than framework-specific servers like Triton or TensorRT for certain models, and it may require additional effort to convert models to the ONNX format.
Platform Compatibility
| Server | Cloud Platforms | On-Premises | Edge Devices |
|---|---|---|---|
| Triton | AWS, Azure, GCP | Yes | Yes (with NVIDIA GPUs) |
| TensorRT | AWS, Azure, GCP | Yes | Yes (with NVIDIA GPUs) |
| MXNet Serving | AWS, Azure, GCP | Yes | Yes |
| ONNX Runtime | AWS, Azure, GCP | Yes | Yes |
Choosing the Right Server
The best inference server for LLM operationalization depends on your specific needs and priorities. Consider the following factors:
- Performance: If raw performance is paramount, Triton or TensorRT on NVIDIA GPUs are strong contenders.
- Model compatibility: Choose a server that supports your chosen LLM framework or can convert it to a compatible format (e.g., ONNX).
- Platform requirements: Consider your deployment environment (cloud, on-premises, edge) and choose a server with compatible options.
- Ease of use: If ease of setup and management is important, MXNet Serving or ONNX Runtime might be better choices.
By carefully evaluating these factors, you can select the optimal inference server to unlock the full potential of your LLMs in production.
Additional Considerations
- Security: Ensure the chosen server implements robust security measures to protect sensitive data.
- Scalability: Choose a server that can scale horizontally to meet increasing demands.
- Cost: Consider the licensing costs and resource requirements of each server.
In conclusion, NVIDIA Triton, TensorRT, Apache MXNet Serving, and ONNX Runtime all offer compelling solutions for LLM operationalization. By understanding their strengths, limitations, and compatibility information, you can make an informed decision that aligns with your specific requirements and ensures the success of your LLM deployments.