

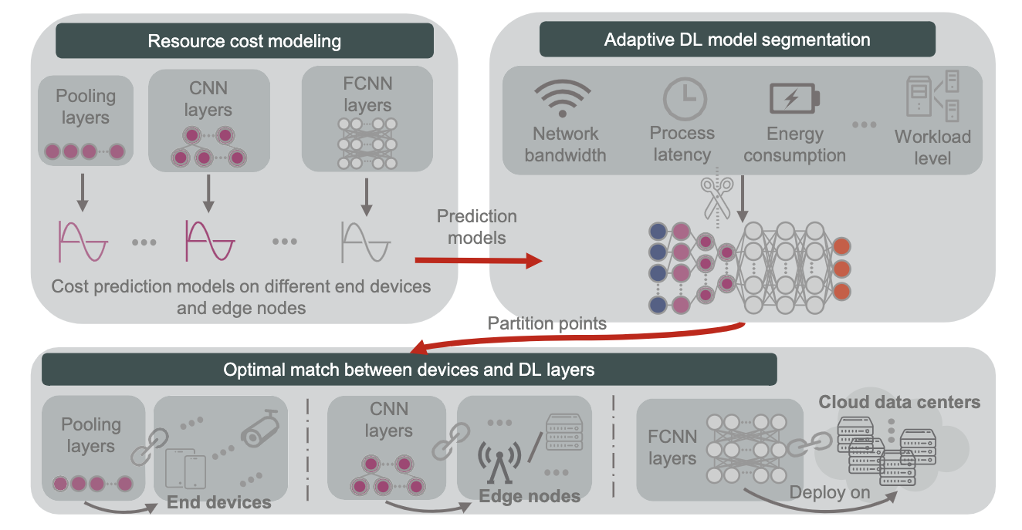
The image shows a diagram of a deep learning model that is divided into four layers: pooling layers, convolutional neural network (CNN) layers, fully connected neural network (FCNN) layers, and prediction model layers. The model is segmented into three parts: end devices, edge nodes, and cloud data centers. The red arrow shows the optimal match between devices and DL layers.
The pooling layers are the first layer of the model and they are responsible for reducing the dimensionality of the input data. The CNN layers are the next layer of the model and they are responsible for extracting features from the data. The FCNN layers are the final layer of the model and they are responsible for making predictions.
The end devices are the devices that collect the data. They are typically small and have limited computing resources. The edge nodes are the devices that process the data. They are larger than end devices and have more computing resources. The cloud data centers are the devices that store the data and train the model. They are the largest and have the most computing resources.
The segmentation of the model is done based on the amount of computing resources that are required by each layer. The pooling and CNN layers require the least amount of computing resources, so they are placed on the end devices. The FCNN layers require more computing resources, so they are placed on the edge nodes. The prediction model layers require the most computing resources, so they are placed in the cloud data centers.
This segmentation has several advantages. First, it reduces the amount of data that needs to be sent to the cloud, which saves bandwidth. Second, it reduces the latency of the model, which means that it can make predictions more quickly. Third, it reduces the energy consumption of the model, which saves battery life on end devices.
The rise of edge computing has brought artificial intelligence (AI) closer to the data it interacts with. This distributed approach, where models are segmented across end devices, edge nodes, and cloud data centers, offers significant advantages in terms of latency, bandwidth, and energy consumption. However, deploying large, complex models at the edge can be challenging due to resource constraints. This is where parametric pruning comes in, acting as a scalpel to trim the fat from models, making them leaner and meaner for edge deployment. Pruning involves removing redundant or insignificant connections (parameters) from the model. Imagine identifying and snipping away connections in the neural network that contribute little to the overall accuracy. By doing so, we can:
- Reduce model size: A smaller model translates to less memory footprint and lower processing demands, making it ideal for deployment on resource-constrained edge devices.
- Improve inference speed: With fewer parameters to juggle, the model can make predictions faster, reducing latency and enhancing real-time performance.
- Minimize energy consumption: Pruning reduces the computational workload, leading to lower power consumption on edge devices, extending battery life.
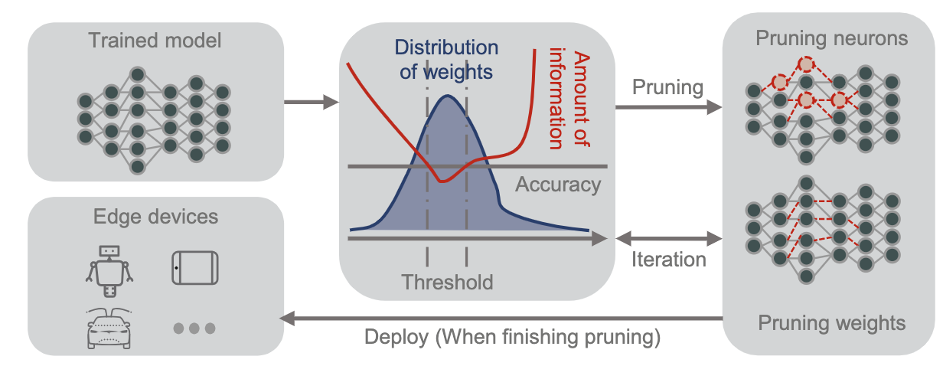
The diagram above can be adapted to incorporate pruning by adding a pruning stage between the layers. This stage would analyze the weights and connections in each layer and identify candidates for removal based on various criteria, such as magnitude, contribution to accuracy, or redundancy. The pruned weights can be set to zero or merged with neighboring connections, effectively shrinking the model size.
Choosing the right pruning technique and granularity is crucial. Pruning too aggressively can lead to accuracy degradation, so finding the sweet spot between model size reduction and performance preservation is key. Several automated pruning algorithms have been developed to navigate this trade-off effectively.
In conclusion, parametric pruning emerges as a powerful tool for optimizing AI models for edge deployment. By strategically removing redundant parameters, we can achieve significant reductions in model size, leading to faster inference, lower power consumption, and ultimately, a more efficient and performant edge AI experience. As the edge computing landscape continues to evolve, expect to see pruning techniques become even more sophisticated and integrated into the fabric of distributed AI architectures.