

Workflow to deliver Trust in Data
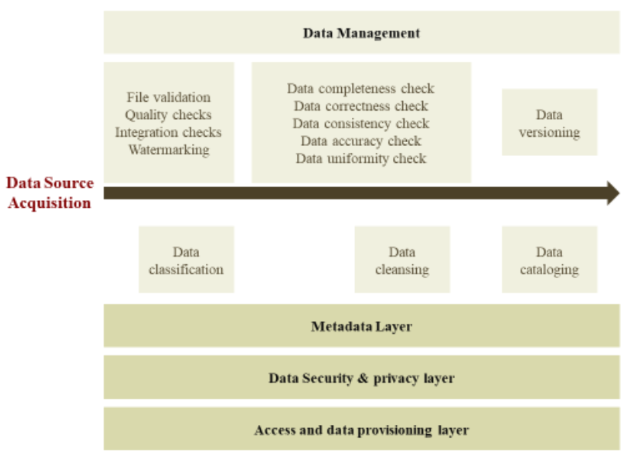
Data Analytics as Product Development System
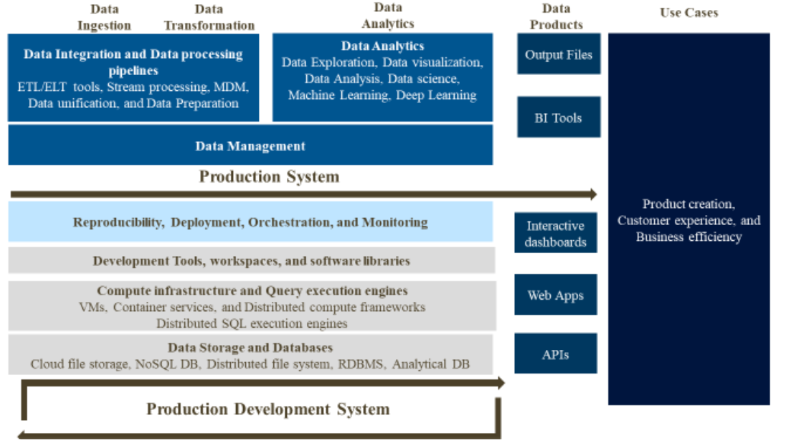
Enterprse Data Architecture Upgrade
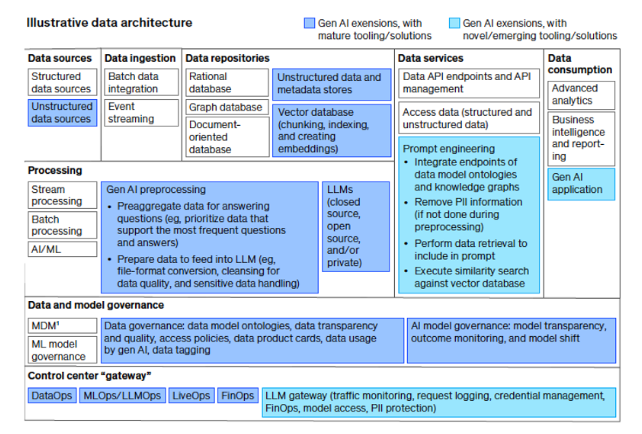
Generative AI (GenAI) holds immense potential, but its success hinges on one crucial element often overlooked: trust in the data that fuels it. Just like the sturdiness of a building relies on its foundation, GenAI’s effectiveness rests on the integrity and reliability of the data it utilizes. This emphasis on trust becomes even more critical when comparing the data processing pipelines of standard data products and GenAI Large Language Models (LLMs).
The Pillars of Trust: From Standard Processes to LLM Enhancements
The journey towards trustworthy data in GenAI begins with established best practices:
- Data Acquisition: Gathering data from diverse sources like text corpora, code repositories, and web archives requires meticulous attention to ethics and responsible sourcing. LLMs often demand additional considerations, such as ensuring data diversity and mitigating bias present in historical information.
- Data Management: Cleansing, organizing, and storing data effectively is crucial. Deduplication, formatting, and version control remain essential, but LLMs add layers of complexity. Data provenance becomes paramount, requiring tools to track data origin and transformations for transparency and auditability.
- Data Processing: Transforming data into a format digestible by the LLM involves tokenization, normalization, and vectorization. For LLMs, data augmentation techniques like back translation, synonym replacement, and noise injection come into play, enriching the training data and fostering robustness against unseen examples.
- Model Training: Training the LLM on processed data involves multiple epochs to fine-tune it for specific applications. LLM training demands significant computational resources, often necessitating cloud-based solutions for scalability and efficiency.
- Model Evaluation: Evaluating the LLM’s performance on a validation set helps identify areas for improvement. LLMs require specific evaluation metrics that assess not just accuracy but also aspects like coherence, fairness, and absence of bias.
- Deployment: Deploying the LLM to a production environment demands robust security measures and monitoring systems to ensure responsible and ethical use. LLMs processing sensitive data necessitate additional safeguards and compliance considerations.
Beyond the Standard: Unlocking GenAI’s True Potential
By diligently adhering to these principles and incorporating LLM-specific enhancements, we ensure GenAI is built on a foundation of trustworthy data. This translates to several benefits:
- Improved model performance: High-quality data leads to more accurate, reliable, and unbiased outcomes from the LLM.
- Enhanced security and privacy: Robust data governance protects sensitive information and builds trust with users.
- Greater scalability and flexibility: The foundation can seamlessly adapt to growing data volumes and model complexity.
- Wider range of applications: Trustworthy GenAI unlocks ethical and responsible adoption across various domains.
However, the benefits extend beyond model performance. Operationalizing an LLM empowers organizations to:
- Automate tasks: Generate creative content, write code, or answer customer questions with unparalleled efficiency.
- Personalize experiences: Tailor recommendations, content, or interactions to individual user preferences for deeper engagement.
- Gain deeper insights: Uncover hidden patterns and trends in massive datasets that might elude human analysis.
By prioritizing trust in data and embracing its transformative power, GenAI can truly become a driving force for innovation and progress. Remember, this is just the beginning. As the field evolves, so will our understanding of trust in data and its impact on GenAI. By continuously refining our practices and fostering collaboration, we can unlock the full potential of this powerful technology for a better future.